 我們與在烏克蘭的朋友和同事站在一起。為了在這個時刻支持烏克蘭,請
我們與在烏克蘭的朋友和同事站在一起。為了在這個時刻支持烏克蘭,請服務效能監控 (SPM)
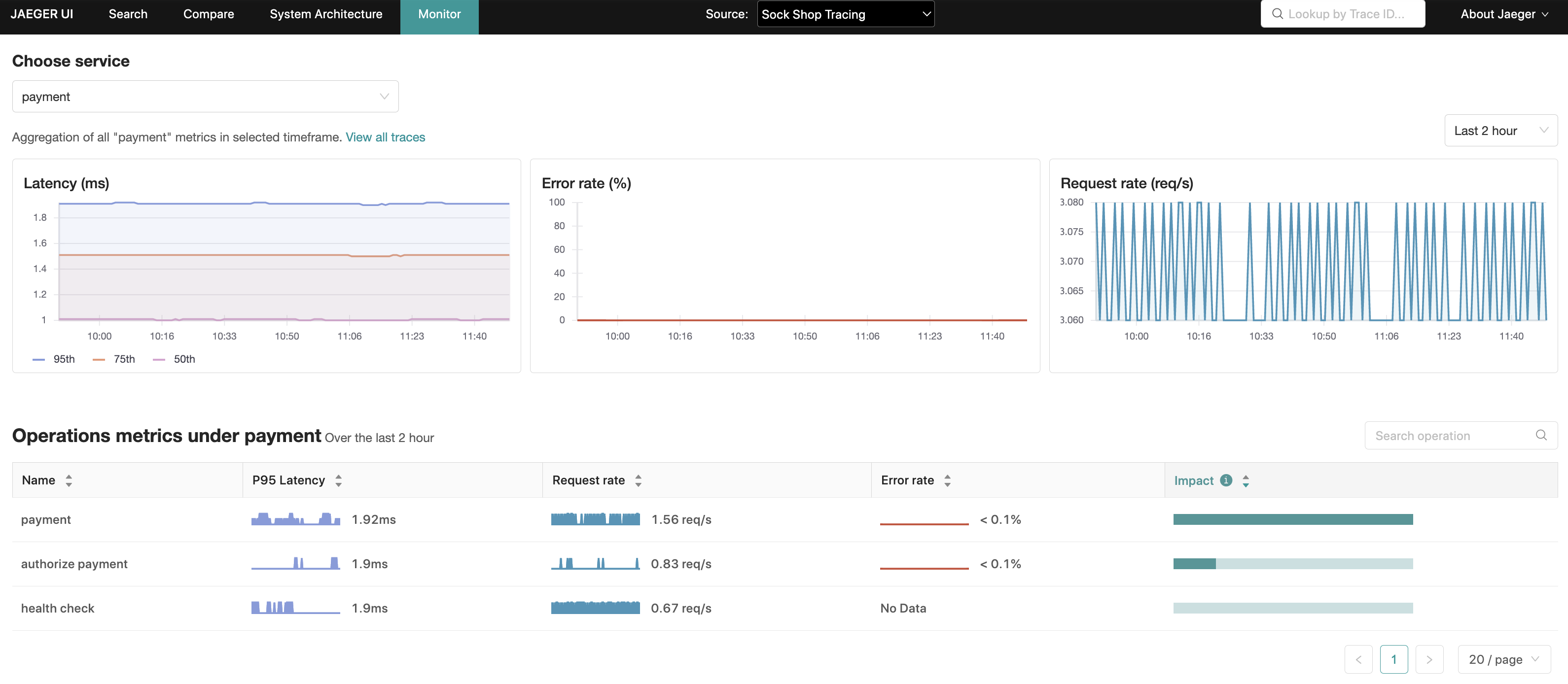
此功能在 Jaeger UI 中以「監控」標籤呈現,其動機在於協助識別有趣的追蹤 (例如,高 QPS、緩慢或錯誤的請求),而無需預先知道服務或操作名稱。
它基本上是透過匯總 span 資料以產生 RED (請求、錯誤、持續時間) 指標來實現。
潛在的使用案例包括
- 在整個組織中或在請求鏈中已知的依賴服務上進行部署後健全性檢查。
- 在收到問題警示時進行監控和根本原因分析。
- 為 Jaeger UI 的新使用者提供更好的入門體驗。
- 長期趨勢分析 QPS、錯誤和延遲。
- 容量規劃。
UI 功能概述
「監控」標籤提供服務層級的匯總,以及服務內的操作層級匯總,包括請求速率、錯誤率和持續時間 (P95、P75 和 P50),也稱為 RED 指標。
在操作層級的匯總中,「影響」指標 (計算為延遲和請求速率的乘積) 是另一個訊號,可用於排除可能自然具有高延遲設定檔的操作 (例如,每日批次工作),或者反過來強調延遲排名較低但具有高 RPS (每秒請求數) 的操作。
根據這些匯總,Jaeger UI 能夠使用相關的服務、操作和回溯期間預先填入追蹤搜尋,從而縮小這些更具吸引力的追蹤的搜尋空間。
開始使用
可在 Jaeger 儲存庫 中找到本地可執行的設定,以及如何執行它的說明。
此功能可以從頂部選單上的「監控」標籤存取。
此示範包含 Microsim ; 一個微服務模擬器,用於產生追蹤資料。
如果偏好手動產生追蹤,則可以透過 docker 啟動 範例應用程式:HotROD。請務必在 docker run 命令中加入 --net monitor_backend。
架構
Jaeger 針對「監控」標籤查詢的 RED 指標,是 OpenTelemetry Collector 收集的 span 資料結果,然後由其管道中設定的 SpanMetrics Connector 元件匯總。
這些指標最終由 OpenTelemetry Collector (透過 Prometheus 匯出器) 匯出到與 Prometheus 相容的指標儲存區。
務必強調這是一個「唯讀」功能,因此,僅與 Jaeger Query 元件 (和 All In One) 相關。
衍生的時間序列
儘管更屬於 OpenTelemetry Collector 的範圍內,但了解當部署 SPM 時,SpanMetrics Connector 將在指標儲存區中產生的其他指標和時間序列,有助於進行容量規劃,這也是值得的。
請參閱 Prometheus 文件 ,其中涵蓋指標名稱、類型、標籤和時間序列的概念;本節的其餘部分將使用這些術語。
將會建立兩個指標名稱
calls_total- 類型:計數器
- 描述:計算 span 的總數,包括錯誤的 span。呼叫計數與錯誤透過
status_code標籤區分。錯誤被定義為任何具有標籤status_code = "STATUS_CODE_ERROR"的時間序列。
[命名空間_]持續時間_[單位]- 類型:直方圖
- 描述:span 持續時間/延遲的直方圖。在底層,Prometheus 直方圖會建立許多時間序列。為了說明,假設未設定命名空間且單位為
milliseconds(毫秒)。duration_milliseconds_count:直方圖中所有 bucket 的資料點總數。duration_milliseconds_sum:所有資料點值的總和。duration_milliseconds_bucket:由n個時間序列組成的集合(其中n是持續時間 bucket 的數量),每個持續時間 bucket 由le(小於或等於)標籤識別。每個 span 都會遞增具有最低le且le >= span 持續時間的duration_milliseconds_bucket計數器。
以下公式旨在提供有關建立新時間序列數量的指南。
num_status_codes * num_span_kinds * (1 + num_latency_buckets) * num_operations
Where:
num_status_codes = 3 max (typically 2: ok/error)
num_span_kinds = 6 max (typically 2: client/server)
num_latency_buckets = 17 default
代入這些數字,假設使用預設配置
max = 324 * num_operations
typical = 72 * num_operations
注意
- 在 spanmetrics 連接器中設定的自訂持續時間 bucket 或維度 將會改變上述計算。
- SPM 不支援查詢自訂維度,將會被匯總。
設定
啟用 SPM
需要以下設定才能啟用 SPM 功能
- Jaeger UI
- Jaeger 查詢
- 將
METRICS_STORAGE_TYPE環境變數設定為prometheus。 - 可選:將
--prometheus.server-url(或PROMETHEUS_SERVER_URL環境變數)設定為 prometheus 伺服器的 URL。預設值:https://127.0.0.1:9090。 - 可選:設定
--prometheus.query.support-spanmetrics-connector=true以明確啟用SpanMetrics 連接器 如果您打算使用它。這將在未來成為預設行為。
- 將
API
gRPC/Protobuf
建議以程式方式檢索 RED 指標的方式是透過 jaeger.api_v2.metrics.MetricsQueryService gRPC 端點,該端點在 metricsquery.proto IDL 檔案中定義。
HTTP JSON
由 Jaeger UI 的「監視」標籤在內部使用,以填入其視覺化的指標。
請參閱 此 README 檔案 ,以取得 HTTP API 的詳細規格。
疑難排解
檢查 /metrics 端點
/metrics 端點可用於檢查是否收到特定服務的 span。/metrics 端點由管理連接埠提供服務。假設 Jaeger all-in-one 和查詢分別在名為 all-in-one 和 jaeger-query 的主機下可用,以下是一些範例 curl 呼叫以取得指標
$ curl http://all-in-one:14269/metrics
$ curl http://jaeger-query:16687/metrics
以下指標最受關注
# all-in-one
jaeger_requests_total
jaeger_latency_bucket
# jaeger-query
jaeger_query_requests_total
jaeger_query_latency_bucket
每個指標都會有以下每個操作的標籤
get_call_rates
get_error_rates
get_latencies
get_min_step_duration
如果一切運作正常,則標籤為 result="ok" 的指標應該會遞增,而 result="err" 則保持靜態。例如
jaeger_query_requests_total{operation="get_call_rates",result="ok"} 18
jaeger_query_requests_total{operation="get_error_rates",result="ok"} 18
jaeger_query_requests_total{operation="get_latencies",result="ok"} 36
jaeger_query_latency_bucket{operation="get_call_rates",result="ok",le="0.005"} 5
jaeger_query_latency_bucket{operation="get_call_rates",result="ok",le="0.01"} 13
jaeger_query_latency_bucket{operation="get_call_rates",result="ok",le="0.025"} 18
jaeger_query_latency_bucket{operation="get_error_rates",result="ok",le="0.005"} 7
jaeger_query_latency_bucket{operation="get_error_rates",result="ok",le="0.01"} 13
jaeger_query_latency_bucket{operation="get_error_rates",result="ok",le="0.025"} 18
jaeger_query_latency_bucket{operation="get_latencies",result="ok",le="0.005"} 7
jaeger_query_latency_bucket{operation="get_latencies",result="ok",le="0.01"} 25
jaeger_query_latency_bucket{operation="get_latencies",result="ok",le="0.025"} 36
如果從 Prometheus 讀取指標時發生問題(例如無法連線到 Prometheus 伺服器),則 result="err" 指標將會遞增。例如
jaeger_query_requests_total{operation="get_call_rates",result="err"} 4
jaeger_query_requests_total{operation="get_error_rates",result="err"} 4
jaeger_query_requests_total{operation="get_latencies",result="err"} 8
此時,檢查記錄檔將提供更多深入瞭解以找出問題的根本原因。
查詢 Prometheus
即使上述 Jaeger 指標指出從 Prometheus 成功讀取,圖表仍可能顯示為空白。在這種情況下,直接在 Prometheus 上查詢任何這些指標
duration_bucketduration_milliseconds_bucketduration_seconds_bucketcallscalls_total
您應該預期當服務將 span 發送到 OpenTelemetry 收集器時,這些計數器會遞增。
檢視記錄檔
如果上述指標存在於 Prometheus 中,但未出現在「監視」標籤中,這表示 Jaeger 預期在 Prometheus 中看到的指標與實際可用的指標之間存在差異。
可以透過設定以下環境變數來提高記錄層級來確認這一點
LOG_LEVEL=debug
輸出類似以下的記錄檔
{
"level": "debug",
"ts": 1688042343.4464543,
"caller": "metricsstore/reader.go:245",
"msg": "Prometheus query results",
"results": "",
"query": "sum(rate(calls{service_name =~ \"driver\", span_kind =~ \"SPAN_KIND_SERVER\"}[10m])) by (service_name,span_name)",
"range":
{
"Start": "2023-06-29T12:34:03.081Z",
"End": "2023-06-29T12:39:03.081Z",
"Step": 60000000000
}
}
在此範例中,假設 OpenTelemetry 收集器的 prometheusexporter 引入了重大變更,該變更會將 _total 後綴附加到計數器指標,並在直方圖指標中附加持續時間單位(例如 duration_milliseconds_bucket)。正如我們發現的那樣,Jaeger 正在尋找 calls(和 duration_bucket)指標名稱,而 OpenTelemetry 收集器正在寫入 calls_total(和 duration_milliseconds_bucket)。
在此特定情況下的解決方案是設定環境變數,告知 Jaeger 正規化指標名稱,以便它知道要搜尋 calls_total 和 duration_milliseconds_bucket,如下所示
PROMETHEUS_QUERY_NORMALIZE_CALLS=true
PROMETHEUS_QUERY_NORMALIZE_DURATION=true
檢查 OpenTelemetry 收集器設定
如果 Jaeger 中出現錯誤 span,但沒有對應的錯誤指標
- 檢查 spanmetrics 連接器在 Prometheus 中產生的原始指標(如上所列:
calls、calls_total、duration_bucket等)是否在 span 應屬的指標中包含status.code標籤。 - 如果沒有
status.code標籤,請檢查 OpenTelemetry 收集器設定檔,特別是以下設定是否存在Jaeger 使用此標籤來判斷請求是否錯誤。exclude_dimensions: ['status.code']
檢查 OpenTelemetry 收集器
如果上述 latency_bucket 和 calls_total 指標為空,則可能是 OpenTelemetry 收集器或其上游的任何設定錯誤。
疑難排解時要問的一些問題是
- OpenTelemetry 收集器是否設定正確?
- OpenTelemetry 收集器是否可以連線到 Prometheus 伺服器?
- 服務是否將 span 發送到 OpenTelemetry 收集器?
「監視」標籤中遺失服務/操作
如果服務/操作在「監視」標籤中遺失,但在 Jaeger 追蹤搜尋服務和操作下拉式功能表中可見,則常見的原因是指標查詢中使用的預設 server span 類型。
您看不到的服務/操作可能來自非伺服器 span 類型的 span,例如用戶端或更糟的 unspecified。因此,這是一個檢測資料品質問題,檢測應該設定 span 類型。
預設為 server span 類型的原因是避免在 server 和 client span 類型中重複計算輸入和輸出 span。
執行指標查詢時出現 403
如果記錄檔包含類似以下錯誤:failed executing metrics query: client_error: client error: 403,則可能是 Prometheus 伺服器預期有持有者權杖。
可以將 Jaeger 查詢(和 all-in-one)設定為透過 --prometheus.token-file 命令列參數(或 PROMETHEUS_TOKEN_FILE 環境變數)在指標查詢中傳遞持有者權杖,其值設定為包含持有者權杖的檔案路徑。